


오늘은 Pandas 총 정리를 해보려고 한다. 이전에는 엑셀을 다루는 모듈을 openpyxl 만 썼었는데 엑셀의 내부 data를 가공하는데 Pandas가 좀더 효율적인 것을 깨달았다.
openpyxl은 엑셀의 특정 셀에 접근해서 값을 쓰고 읽어오는데 장점이 있다면 Pandas는 전체적인 표, 전체적인 data를 읽어오고 내가 원하는대로 가공할 수 있다는 것이 장점인 것 같다.
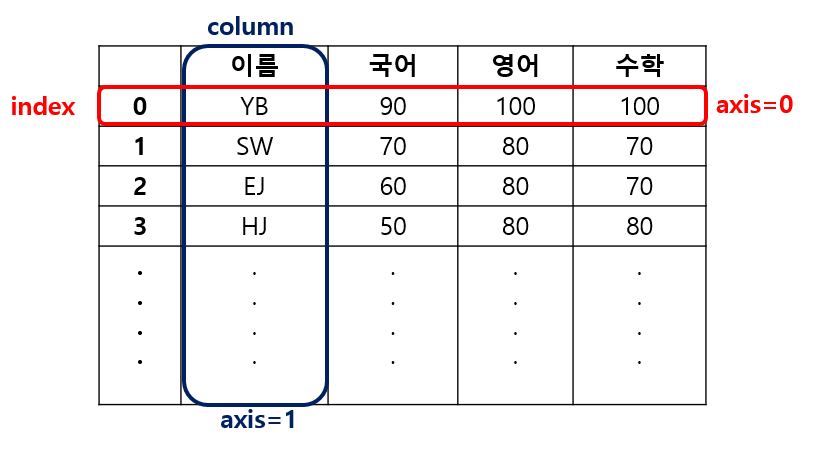
이번에는 Padnas 모듈을 사용하기 위한 기본적인 내용들을 정리하려고 한다. Pandas를 사용하려면 먼저 Series와 Dataframe의 개념을 먼저 알아야 한다. 해당 개념을 이해하기 위해 아래와 같이 간단히 도식화해보았다.
![[Python/파이썬] Pandas 총 정리](https://blog.kakaocdn.net/dn/qe7jx/btsz6e2UXVl/BPvc3z2r8u0MbdJRMFdWL1/img.jpg)
[Python/파이썬] Pandas 총 정리
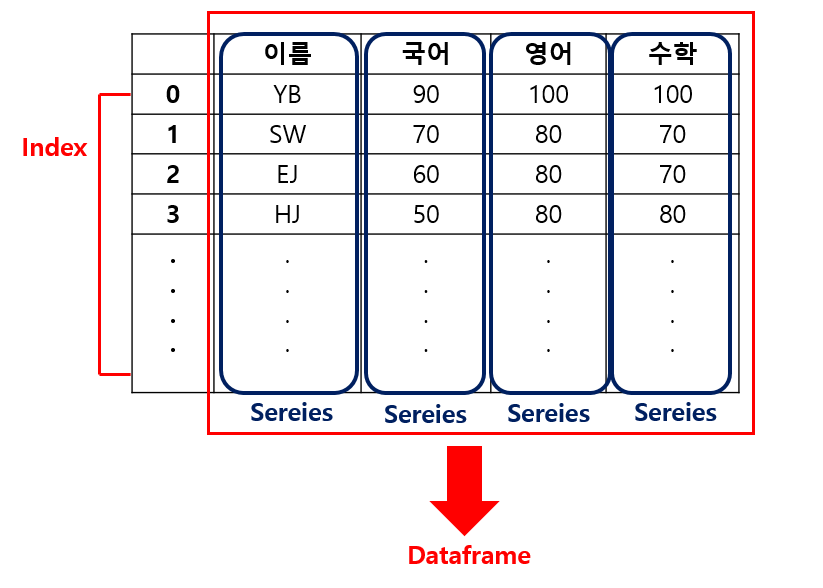
Series, Dataframe 개념
Series : 위 이미지에서 보듯이 각 열(Column) 단위를 Series라고 부른다.
Dataframe : 각 열 단위(Series)가 모여 된 하나의 표를 Dataframe이라고 한다.
Index : Series, Dataframe을 생성하면 인덱싱 번호가 따라다닌다. 인덱스는 Series가 아니다. 위 이미지에는 숫자로 되어있지만
내가 원하는 인덱스 형태로 변경할 수 있다.
1. Series 다뤄보기
1) Series 객체 생성해보기
-. Series는 Pandas 모듈의 클래스인 것을 아래 결과를 통해 알 수 있다.
-. Series 전체를 출력하면 인덱싱 번호가 붙어서 출력 된다.
-. 리스트처럼 각각 인덱싱 번호로 출력할 수 있다.
<코드>
import pandas as pd
#price라는 Series 생성
price = pd.Series([500, 1000, 2000, 4000])
print("Series type:")
print(type(price)) #Series는 pandas의 클래스
print("Series 전체 출력")
print(price)
print("Series 인덱싱")
print(price[0])
print(price[1])
Series type:
<class 'pandas.core.series.Series'>
Series 전체 출력
0 500
1 1000
2 2000
3 4000
dtype: int64
Series 인덱싱
500
1000
2) 인덱스를 직접 입력해보기
: 위 1) 코드에서 Series 생성시 인덱스를 내가 원하는 형식으로 변경할 수 있다.(설정하지 않으면 숫자 인덱스)
<코드>
import pandas as pd
#price라는 Series 생성
price = pd.Series([500, 1000, 2000, 4000], index =['2021-01-01', '2021-02-02', '2021-03-03', '2021-04-04'])
print("Series 전체 출력")
print(price)
Series 전체 출력
2021-01-01 500
2021-02-02 1000
2021-03-03 2000
2021-04-04 4000
3) 인덱스, Series의 각 요소에 접근해보기
Series의 속성인 .index, .values를 통해 인덱스나 각 요소를 for문을 통해 접근할 수 있다.
<코드>
import pandas as pd
#price라는 Series 생성
price = pd.Series([500, 1000, 2000, 4000], index =['2021-01-01', '2021-02-02', '2021-03-03', '2021-04-04'])
#index 출력하기
for date in price.index:
print(date)
#인덱스에 따른 값 출력하기
for pri in price.values:
print(pri)
2021-01-01
2021-02-02
2021-03-03
2021-04-04
500
1000
2000
4000
4) Series 끼리 사칙연산
-. Series 끼리 사칙연산이 가능하다.
-. 사칙연산을 한 결과는 또 다른 Series이다.
<코드>
import pandas as pd
#price1,2 라는 Series 생성
price1 = pd.Series([500, 1000, 2000, 4000], index =['2021-01-01', '2021-02-02', '2021-03-03', '2021-04-04'])
price2 = pd.Series([5000, 10000, 20000, 40000], index =['2021-02-02', '2021-01-01', '2021-04-04', '2021-03-03'])
#Series + Series
sum = price1 + price2
print(sum)
2021-01-01 10500
2021-02-02 6000
2021-03-03 42000
2021-04-04 24000
dtype: int64
2. Dataframe 다뤄보기
1) Dataframe 생성해보기 (위 이미지를 기준으로)
-. 아래와 같이 딕셔너리 형태로 Dataframe을 생성할 수 있다.
-. 결과에서 보면 각 Column인 '국어', '영어','수학' 열은 Series이다. (Series가 모여서 Dataframe이 된다.)
<코드>
import pandas as pd
#3개의 key : value를 가진 딕셔너리
raw_data = {'국어' : [90, 70, 60, 50],
'영어' : [100, 80, 80, 80],
'수학' : [100, 70, 70, 80]}
#위 딕셔너리를 받아서 그대로 dataframe으로 생성
df = pd.DataFrame(raw_data)
print("df의 type:")
print(type(df))
print(df)
df의 type:
<class 'pandas.core.frame.DataFrame'>
국어 영어 수학
0 90 100 100
1 70 80 70
2 60 80 70
3 50 80 80
2) Dataframe의 Column(열) 순서 바꿔보기
-. Dataframe 생성시 'columns' 파라미터를 사용하면 Column의 순서를 바꾸는 것도 가능하다.
<코드>
import pandas as pd
#3개의 key : value를 가진 딕셔너리
raw_data = {'국어' : [90, 70, 60, 50],
'영어' : [100, 80, 80, 80],
'수학' : [100, 70, 70, 80]}
#위 딕셔너리를 받아서 그대로 dataframe으로 생성
df = pd.DataFrame(raw_data, columns=['영어','국어','수학'])
print(df)
영어 국어 수학
0 100 90 100
1 80 70 70
2 80 60 70
3 80 50 80
3) Dataframe의 인덱스를 따로 설정해보기
-. Dataframe 생성시 'index' 파라미터를 사용하면 인덱스를 따로 설정할 수 있다.
-. 인덱스를 입력할시 리스트 or 튜플 형태로 입력 가능
-. Dataframe이 인덱스를 설정할 때 Column의 data가 4개라면 반드시 index도 4개로 설정해야 한다.(다르면 오류 남)
<코드>
import pandas as pd
#3개의 key : value를 가진 딕셔너리
raw_data = {'국어' : [90, 70, 60, 50],
'영어' : [100, 80, 80, 80],
'수학' : [100, 70, 70, 80]}
index_list = ["YB", 'SW', 'EJ', 'HJ'] #튜플로 해도 무관
df = pd.DataFrame(raw_data, columns=['영어','국어','수학'], index = index_list)
print(df)
영어 국어 수학
YB 100 90 100
SW 80 70 70
EJ 80 60 70
HJ 80 50 80
Series와 Dataframe에 대한 개념에 대해 정리하고, pandas 모듈을 통해 어떻게 생성할 수 있는지에 대해 공부했다. pandas 모듈을 활용하면 이미 만들어져있는 엑셀파일이나 csv 파일을 Dataframe으로 만들어 여러 방법으로 가공할 수 있다. 이 가공한 Dataframe을 다시 csv나 엑셀파일로도 만들 수 있다.
나는 엑셀 파일을 활용할 예정이기 때문에 이번 포스팅은 엑셀파일을 Dataframe화 하는 방법에 대해 정리해보려고 한다. 임의의 엑셀파일 df_test.xlsx를 생성하고 아래와 같이 시트를 작성해보았다.(시트명 : Sheet1)
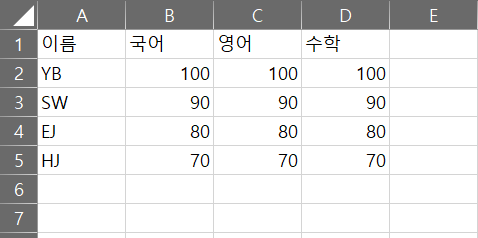
1. 엑셀 파일(.xlsx)를 Dataframe으로 생성하는 법
※ 기본 사용법
import pandas as pd
pd.read_excel("파일명(경로포함)", engine = "openpyxl)-. pandas의 read_excel 함수를 사용하면 된다. 작성 중인 .py파일과 같은 경로에 있으면 파일명만 넣으면 된다.
-. xlsx 확장자의 엑셀파일을 dataframe 하려면 openpyxl 엔진을 활용해야 한다.
-. 위 사용법에 따라 df_test.xlsx 파일 내부 내용을 dataframe화 해보자.
<코드>
import pandas as pd
#df_test.xlsx 파일을 dataframe으로 변경
df = pd.read_excel("df_test.xlsx", engine = "openpyxl")
print(df)
이름 국어 영어 수학
0 YB 100 100 100
1 SW 90 90 90
2 EJ 80 80 80
3 HJ 70 70 70
2. read_excel 함수의 각 옵션
read_excel 함수에는 여러 파라미터가 있다. 파라미터를 활용하면 dataframe을 내가 원하는 방향으로 좀 더 쉽게할 수 있는 것 같다. 대표적으로 잘 쓸 것같은 파라미터를 정리해보려고 한다. 엑셀파일은 위 예시 파일 그대로 활용한다.
아래는 대표적인 파라미터만 몇개 기재한거라 더 많은 내용을 참고하려면 다른 블로그에서 잘 정리해주신 분이 있어서 하단의 참고링크를 기재하였음.
1) sheet_name
-. 엑셀 파일에 여러 시트가 있을 경우에 자기가 원하는 시트를 Dataframe화 하라면 사용하는 파라미터이다.
<코드>
import pandas as pd
#여러 시트가 있을 경우 시트명을 직접 입력하여 dataframe화
df = pd.read_excel("df_test.xlsx", engine = "openpyxl", sheet_name="Sheet1")
print(df)
이름 국어 영어 수학
0 YB 100 100 100
1 SW 90 90 90
2 EJ 80 80 80
3 HJ 70 70 70
2) header
-. header는 행의 제목이 실행되는 위치를 지정할 수 있다.
-. 예를 들어 제목행이 아래처럼 3행에 있는 경우 header=2를 입력하면 된다.
-. 2를 입력하는 이유는 파이썬의 인덱싱 시작 숫자는 0이기 때문이다. (0,1,2이므로 3행은 2로 입력)
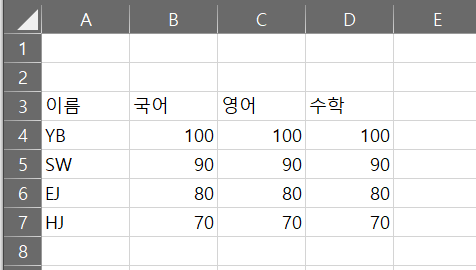
<코드>
import pandas as pd
#header를 통해 컬럼명 위치 지정 가능
df = pd.read_excel("df_test.xlsx", engine = "openpyxl", header=2)
print(df)
이름 국어 영어 수학
0 YB 100 100 100
1 SW 90 90 90
2 EJ 80 80 80
3 HJ 70 70 70
3) index_col
-. 특정 열(Column)을 인덱스로 지정하고 싶을 때 사용한다.
-. 만약 위 Dataframe에서 '이름' 열을 인덱스로 하려면 2가지 방법이 있다.
index_col = "이름" 또는 index_col = 0
-. 0을 입력하는 이유는 파이썬 인덱싱이 첫번째가 0부터 시작하기 때문이다.(이름열이 Dataframe에서 첫번째임)
<코드>
import pandas as pd
#index_col = 0으로 입력해도 결과는 동일
df = pd.read_excel("df_test.xlsx", engine = "openpyxl", index_col="이름")
print(df)
국어 영어 수학
이름
YB 100 100 100
SW 90 90 90
EJ 80 80 80
HJ 70 70 70
4) usecols
-. usecols는 엑셀 파일에서 특정 열(Column)들만 골라서 Dataframe화 할 때 사용한다.
-. 위 엑셀파일에서 이름이랑 영어점수만 Dataframe으로 생성하고 싶다면 usecols = "A, C" 를 입력한다.
-. 알파벳말고 숫자 인덱싱으로도 접근 가능하다. A,C열이면 usecols = [0, 2]를 입력해도 같은 결과이다.
<코드>
import pandas as pd
#원하는 열만 데이터프레임화
df = pd.read_excel("df_test.xlsx", engine = "openpyxl", usecols = "A,C")
print(df)
이름 영어
0 YB 100
1 SW 90
2 EJ 80
3 HJ 70
5) names
-. Column 명의 제목을 바꾸고 싶을 때 사용하는 파라미터
-. 이름, 국어, 영어, 수학을 'Name', 'Korean', 'English', 'Math'로 바꿔보자.
-. 주의할 사항은 해당 dataframe의 Column 숫자만큼 names를 설정해야 한다.
(아래처럼 원래 Column이 4개였으면 names의 리스트 요소도 4개
<코드>
import pandas as pd
#원하는 열만 데이터프레임화
df = pd.read_excel("df_test.xlsx", engine = "openpyxl", names=['Name', "Korean", "English","Math"])
print(df)
Name Korean English Math
0 YB 100 100 100
1 SW 90 90 90
2 EJ 80 80 80
3 HJ 70 70 70
3. Dataframe을 다시 엑셀파일(.xlsx)로 저장하기
-. Dataframe을 다시 엑셀파일(.xlsx)로 저장할 수 있다.
-. Dataframe의 인덱스 때문에 원래 형태와는 다른 포맷이 출력된다.(아래 참고)
<코드>
import pandas as pd
#원하는 열만 데이터프레임화(A,B,C)
df = pd.read_excel("df_test.xlsx", engine = "openpyxl", usecols=[0,1,2])
print(df)
#데이터프레임 엑셀파일로 추출
df.to_excel('test_save.xlsx')
이름 국어 영어
0 YB 100 100
1 SW 90 90
2 EJ 80 80
3 HJ 70 70
다음 포스팅에서는 만들어진 Dataframe을 가공하는 방법이나 문자열을 찾는 방법 등의 padnas 함수를 정리해 볼
예정이다.
만들어진 Dataframe을 가공하고 조회하는 방법에 대해 일부 정리하였다. 아래와 같은 목록으로 정리할 예정이다. 이번 편에서는 1), 2)를 다룰 예정이다. 내용을 정리하면서 yg's blog라는 github를 참고하였다.
(참고링크는 하단에 기재 함)
| 1) Dataframe의 행, 열 이름 변경 2) Dataframe 조회 -. 인덱싱 -. 슬라이싱 -. 열 조회 -. 원소 조회 3) 행 열 추가하기 4) 행 삭제하기(drop) 4) 원소값 바꾸기 5) 결측치(NaN) 관련 |
이전 편에서 만들었던 dataframe을 그대로 활용할 예정이다.
* Dataframe 생성 코드
import pandas as pd
#dataframe 생성
df = pd.read_excel("df_test.xlsx", engine="openpyxl")
print(df)
이름 국어 영어 수학
0 YB 100 100 100
1 SW 90 90 90
2 EJ 80 80 80
3 HJ 70 70 70
1. Dataframe의 index, column 수정
1) index와 column 조회
-. 인덱스와 컬럼명을 조회하려면 아래와 같이 코드 사용
index명 : 'dataframe명'.index
column명 : 'dataframe명'.columns
-. 인덱스의 경우 숫자 0~3이어서 start=0, stop=4, step1이라고 출력 된다.
#print(df.columns)의 결과
Index(['이름', '국어', '영어', '수학'], dtype='object')
#print(df.index)의 결과
RangeIndex(start=0, stop=4, step=1)
2) index와 column명 변경
-. 인덱스 및 컬럼명을 바꾸려면 아래 코드와 같이 하면 작성하면 된다.
<코드>
import pandas as pd
#dataframe 생성
df = pd.read_excel("df_test.xlsx", engine="openpyxl")
#인덱스 바꾸기
df.index = ['사람1', '사람2', '사람3', '사람4']
#컬럼명 바꾸기
df.columns = ['Name', 'Korean', 'English', 'Math']
print(df)
Name Korean English Math
사람1 YB 100 100 100
사람2 SW 90 90 90
사람3 EJ 80 80 80
사람4 HJ 70 70 70
-. 특정 열이나 인덱스만 바꾸고 싶으면 rename( ) 함수를 사용한다.
-. rename 함수사용시 내부 파라미터로 inplace=True를 반드시 넣어줘야 dataframe 원본이 수정된다.
<코드>
#특정 인덱스만 변경하기
df.rename(index={'사람1':'Person1', '사람3':"Person3"}, inplace=True)
#특정 컬럼명만 변경하기
df.rename(columns={'Name':'성명', 'Math':"수학"}, inplace=True)
print(df)
성명 Korean English 수학
Person1 YB 100 100 100
사람2 SW 90 90 90
Person3 EJ 80 80 80
사람4 HJ 70 70 70
2. 데이터프레임 조회하기
다시 처음과 동일한 dataframe 을 생성하였다.
<코드>
import pandas as pd
#dataframe 생성
df = pd.read_excel("df_test.xlsx", engine="openpyxl")
df.index = ['사람1', '사람2', '사람3', '사람4']
print(df)
이름 국어 영어 수학
사람1 YB 100 100 100
사람2 SW 90 90 90
사람3 EJ 80 80 80
사람4 HJ 70 70 70
1) 인덱싱하기
-. 인덱싱 또는 슬라이싱할 때 아래 2개 함수를 이용한다.
loc( ) : 이름으로 접근하기
iloc( ) : 숫자로 접근하기(행위치값 0부터~)
-. loc 사용하기 : 인덱스명에 대한 행 값들을 읽어오며, 결과는 Series type이 된다.
<코드>
name = df.loc['사람3']
print(name)
print(type(name))
이름 EJ
국어 80
영어 80
수학 80
Name: 사람3, dtype: object
<class 'pandas.core.series.Series'>
-. iloc 사용하기 : 행위치값으로 읽어온다. 첫줄의 위치값은 0이다. 마찬가지로 결과는 Series이다.
<코드>
name = df.iloc[0]
print(name)
print(type(name))
이름 YB
국어 100
영어 100
수학 100
Name: 사람1, dtype: object
<class 'pandas.core.series.Series'>
2) 슬라이싱하기 : loc, iloc를 활용하여 범위로 읽어올 수 있다.
-. loc : 인덱스명으로 슬라이싱할 수 있다. 아래 코드는 사람1~사람3까지 행 data를 읽어온다. 결과는 dataframe이다.
<코드>
name = df.loc['사람1':'사람3']
print(name)
print(type(name))
이름 국어 영어 수학
사람1 YB 100 100 100
사람2 SW 90 90 90
사람3 EJ 80 80 80
<class 'pandas.core.frame.DataFrame'>
-. iloc : 행위치값으로 슬라이싱할 수 있다. 첫행값은 0이다. 위 결과와 똑같이 출력하려면 iloc[0:3]를 작성한다.
행위치값으로 슬라이싱할 경우 마지막 숫자(3행)는 포함하지 않아서 마지막 숫자는 +1을 해야한다.
<코드>
name = df.iloc[0:3]
print(name)
print(type(name))
이름 국어 영어 수학
사람1 YB 100 100 100
사람2 SW 90 90 90
사람3 EJ 80 80 80
<class 'pandas.core.frame.DataFrame'>
-. 2행단위로 조회, 역순으로 조회하는 방법은 아래와 같이 작성한다.
<코드>
#2행단위로 조회
row1 = df.iloc[::2] #df.iloc[0:3:2]랑 동일
print(row1)
#역순으로 조회
row2 = df.iloc[::-1]
print(row2)
이름 국어 영어 수학
사람1 YB 100 100 100
사람3 EJ 80 80 80
이름 국어 영어 수학
사람4 HJ 70 70 70
사람3 EJ 80 80 80
사람2 SW 90 90 90
사람1 YB 100 100 100
3) 열을 선택하는 방법
-. 아래 처럼 열단위로 컬럼을 조회할 수 있다.
<코드>
column1 = df['국어'] #컬럼 1개
column2 = df[['국어','수학']] #컬럼 2개
column3 = df.영어 #컬럼 1개
print("컬럼 1개만:")
print(column1)
print("컬럼 2개:")
print(column2)
print("또다른 표현:")
print(column3)
컬럼 1개만:
사람1 100
사람2 90
사람3 80
사람4 70
Name: 국어, dtype: int64
컬럼 2개:
국어 수학
사람1 100 100
사람2 90 90
사람3 80 80
사람4 70 70
또다른 표현:
사람1 100
사람2 90
사람3 80
사람4 70
Name: 영어, dtype: int64
4) dataframe에서 특정 값 조회하기(원소)
-. index를 '이름'열로 설정하여 dataframe 재생성하였음.
<코드>
import pandas as pd
#dataframe 생성, 이름열을 인덱스로 설정
df = pd.read_excel("df_test.xlsx", engine="openpyxl", index_col="이름")
print(df)
국어 영어 수학
이름
YB 100 90 80
SW 70 60 50
EJ 40 30 20
HJ 10 5 1
-. loc과 iloc 함수를 사용하면 특정 원소만 가져오기 가능.
4가지 표현법으로 정리하였다.
<코드>
#YB 수학점수 : loc 사용해보기
score1 = df.loc['YB', '수학']
print('YB 수학점수 :' ,score1)
#SW 영어점수 : iloc 사용해보기
score2 = df.iloc[1, 1] #행,열 모두 0,1,2 인덱싱
print("SW 영어점수 :", score2)
#EJ의 국어,영어점수 동시에 가져오기 : loc 사용해보기
score3 = df.loc['EJ', ['국어','영어']]
print("EJ 국어, 영어점수 :","\n", score3)
#HJ의 국어, 수학점수 동시에 가져오기 # iloc 사용해보기
score4 = df.iloc[3,[0,2]] #행, 열 모두 0,1,2인덱싱
print("HJ의 국어,수학점수 :","\n",score4)
국어 영어 수학
이름
YB 100 90 80
SW 70 60 50
EJ 40 30 20
HJ 10 5 1
#score1
YB 수학점수 : 80
#score2
SW 영어점수 : 60
#score3
EJ 국어, 영어점수 :
국어 40
영어 30
Name: EJ, dtype: int64
#score4
HJ의 국어,수학점수 :
국어 10
수학 1
Name: HJ, dtype: int64
ataframe의 행(Row)와 열(Column)을 추가하는 방법에 대해 정리하였다. 엑셀을 평소에 많이 사용하는 만큼 Pandas는 꼼꼼히 정리해볼 예정이다. 이전에 포스팅했던 Outlook 데이터 취합 자동화는 Pandas에 익숙해지고 시도해볼 예정이다.
| 1) Dataframe의 행, 열 이름 변경 2) Dataframe 조회 -. 인덱싱 -. 슬라이싱 -. 열 조회 -. 원소 조회 3) 행 열 추가하기 4) 행 삭제하기(drop) 4) 원소값 바꾸기 5) 결측치(NaN) 관련 |
1. 열(Column)을 추가하는 방법
<코드>
import pandas as pd
#dataframe 생성, 이름열을 인덱스로 설정
df = pd.read_excel("df_test.xlsx", engine="openpyxl", index_col="이름")
print(df)
df['과학'] = 80
print(df)
<결과>
#원본 dataframe
국어 영어 수학
이름
YB 100 90 80
SW 70 60 50
EJ 40 30 20
HJ 10 5 1
#과학 컬럼 추가 후 dataframe
국어 영어 수학 과학
이름
YB 100 90 80 80
SW 70 60 50 80
EJ 40 30 20 80
HJ 10 5 1 80
-. 새로운 컬럼을 추가하고 싶다면 위와 같이 df['추가할 컬럼명'] = value 형태로 사용하면 된다.
-. 단, 새롭게 추가 된 컬럼의 값들은 입력한 value로 통일된다.(과학의 경우 80점으로 통일)
2. 행(Row)를 추가하는 방법
1) loc 이용하기
<코드>
import pandas as pd
#dataframe 생성, 이름열을 인덱스로 설정
df = pd.read_excel("df_test.xlsx", engine="openpyxl", index_col="이름")
print(df)
df.loc['SS']=[100,200,300]
df.loc['YB']=[10,10,10]
print(df)
<결과>
#원본
국어 영어 수학
이름
YB 100 90 80
SW 70 60 50
EJ 40 30 20
HJ 10 5 1
#'SS' 추가, 'YB' 바꾸기
국어 영어 수학
이름
YB 10 10 10
SW 70 60 50
EJ 40 30 20
HJ 10 5 1
SS 100 200 300
-. 이전편에서 인덱싱하기 항목에서 loc( ) 를 설명한적이 있는데 새로운 행을 추가하는 방법에서는 사용법이 좀 다른 것 같다.
서로 헷갈리지 말자.
-. 기본 사용법은 아래와 같다
'dataframe이름'.loc['추가할 인덱스명'] = 컬럼에 맞는 값(리스트 형태, 컬럼수가 맞아야 함.)
-. 이미 있는 인덱스일 경우 덮어씌워지게 된다.
2) append( ) 이용하기
<코드>
import pandas as pd
#dataframe 생성, 이름열을 인덱스로 설정
df = pd.read_excel("df_test.xlsx", engine="openpyxl", index_col=0)
print(df)
#새로운 행 추가, append 사용시 반드시 또다른 df로 정의해주어야 함.
new = {'국어':100, '영어':100, '수학':100}
df2 = df.append(new, ignore_index=True)
print(df2)
<결과>
#원본 df
국어 영어 수학
이름
YB 100 90 80
SW 70 60 50
EJ 40 30 20
HJ 10 5 1
# 결과 : df2 ,4번행 추가(100, 100, 100)
국어 영어 수학
0 100 90 80
1 70 60 50
2 40 30 20
3 10 5 1
4 100 100 100
-. append는 df와 딕셔너리 형태를 합칠 수 있다.(새로운 딕셔너리를 추가할 수 있음)
-. 주석에도 달았지만 append 사용시 반드시 또다른 df로 정의해주어야 한다. df.append만 한다고 원본 df가 수정되진 않는다.
(이 것 때문에 계속 원본이 출력되어 한참 고민 함.)
-. append를 사용하려면 반드시 파라미터에 ignore_index=True를 넣어준다. 해당 파라미터를 True로 설정하면 기존 df의 인덱스를 무시한다. 결과에서 보듯이, 이름이 index였는데 df2 결과에서 숫자 인덱스로 변경되었다.(기존 인덱스 무시 됨.)
-. ignore_index = False는 코드 실행시 에러가 발생한다. 무조건 True로 설정해야 하는 파라미터임.
-. df와 df를 합칠려면 3)의 concat( ) 을 활용해야 한다.
3) concat( )
<코드>
import pandas as pd
#dataframe 생성
df = pd.read_excel("df_test.xlsx", engine="openpyxl")
print(df)
#합칠 dataframe 따로 생성
new = {'이름':['몰라'], '국어':[100], '영어':[100], '수학':[100]}
df2 = pd.DataFrame(new)
print(df2)
#concat통해 합치기
df = pd.concat([df, df2])
print(df)
<결과>
#원본 dataframe
이름 국어 영어 수학
0 YB 100 90 80
1 SW 70 60 50
2 EJ 40 30 20
3 HJ 10 5 1
#합칠 dataframe
이름 국어 영어 수학
0 몰라 100 100 100
#contcat 통해 합친 dataframe
이름 국어 영어 수학
0 YB 100 90 80
1 SW 70 60 50
2 EJ 40 30 20
3 HJ 10 5 1
0 몰라 100 100 100
-. concat( )은 df와 df를 합칠 때 쓴다.
. df를 dictionary 형태로 선언할 때 key 값에 중괄호[ ]를 반드시 붙이자.(에러남)
-. concat()과 비슷하게 merge( ) 가 있는데 concat( )과 차이점은 아래와 같다.
concat : 단순히 2개의 df를 합치는 것
merge : 2개의 df를 공통된 항목을 기준으로 합치는 것
-. merge( )와 concat( )은 다른 포스팅에서 정리 할 예정. 추가로 join( ) 도 있다고 한다.
| 1) Dataframe의 행, 열 이름 변경 2) Dataframe 조회 -. 인덱싱 -. 슬라이싱 -. 열 조회 -. 원소 조회 3) 행, 열 추가하기 4) 행, 열 삭제하기(drop) 4) 원소값 바꾸기 5) 결측치(NaN) 관련 |
이번 편에서는 Dataframe의 행과 열을 삭제하는 방법에 대해 포스팅한다. Pandas에서는 drop( ) 이라는 함수를 통해 행, 열을 삭제할 수 있다. dataframe은 이전 편까지 활용했던 엑셀 파일을 활용한다.
<코드>
import pandas as pd
#dataframe 생성(엑셀 파일 통해 생성)
df = pd.read_excel("df_test.xlsx", engine="openpyxl")
print(df)
이름 국어 영어 수학
0 YB 100 90 80
1 SW 70 60 50
2 EJ 40 30 20
3 HJ 10 5 1
1. Dataframe의 행 삭제
drop( ) 함수 사용법은 간단하다. 행인 경우 index를 통해 접근하거나 특정 조건을 통해 삭제할 수 있다.
1) index 통해 삭제하는 방법
<코드>
df2 = df.drop(index=0, axis=0)
print(df2)
이름 국어 영어 수학
1 SW 70 60 50
2 EJ 40 30 20
3 HJ 10 5 1
-. index=0인 행을 삭제한다.
-. axis=0은 행을 의미한다.
-. 여러 인덱스를 한꺼번에 삭제하고 싶다면 아래와 같이 입력한다.
1,2,3번째 인덱스를 삭제(index=0만 남김)
-. 아래 코드는 행을 삭제한 결과를 'df2'라는 변수에 dataframe을 재할당했다.
<코드>
df2 = df.drop(index=[1,2,3])
print(df2)
이름 국어 영어 수학
0 YB 100 90 80
-. 만약 원본에서 바로 바꾸고 싶다면 inplace=True를 아래처럼 파라미터로 입력해야 한다.
<코드>
df.drop(index = [0,1], inplace=True)
print(df)
이름 국어 영어 수학
2 EJ 40 30 20
3 HJ 10 5 1※ 참고사항 : axis = 0 vs axis = 1
-. axis = 0은 dataframe 행 단위를 수정할 때 필요한 파라미터 값이다.
-. axis = 1은 dataframe 열 단위를 수정할 때 필요한 파라미터 값이다.
-. axis = 1의 경우 정 열을 통째로 수정하는게 아닌 열의 각 요소들을 수정하는 것이다. 아래 참고 링크 기재
-. drop( ) 함수에 index, column이라는 파라미터를 사용하지 않는다면 axis=0 또는 axis=1 파라미터값을 넣어줘야 한다.
예를 들면 아래와 같은 경우를 말한다.
<코드>
df.drop(['이름','국어'], inplace=True)
print(df)
#에러 발생
KeyError: "['이름' '국어'] not found in axis"
-. KeyError가 발생하는 이유는 설정한 axis에서 '이름', '국어'라는 이름을 찾지 못했기 때문이다.
-. axis를 설정하지 않는 경우 기본값은 axis=0이다.
-. 따라서, 위 코드처럼 Column에 접근하려면 axis=1을 넣어줘야 한다.(index로 접근할 때는 axis=0은 생략 해도 됨.
(axis=0이 default 이기 때문)
<코드>
df.drop(['국어','영어'], axis=1, inplace=True)
print(df)
이름 수학
0 YB 80
1 SW 50
2 EJ 20
3 HJ 1
2) 특정 조건을 통해 행을 삭제하는 방법
지금까지 했던 방법은 drop( )을 활용한 방식이고 특정 조건을 만족하는 row(행)만 dataframe으로 생성하는 방법이 있다.(필터링) 아래와 같이 코드를 작성해보자. 조건에 만족하지 않는 행은 삭제된다.
<코드>
df3= df[df['이름'] == 'SW']
print(df3)
이름 국어 영어 수학
1 SW 70 60 50
-. '이름' 열의 'SW'만 필터링하는 조건이다.
-. 조건이므로 '비교연산자'를 사용해야 함을 주의하자.
2. Dataframe의 열 삭제
열 삭제는 행 삭제의 파라미터인 index 를 columns으로 바꿔 사용하면 된다.
<코드>
df4 = df.drop(columns = ['국어', '영어'])
print(df4)
이름 수학
0 YB 80
1 SW 50
2 EJ 20
3 HJ 1
-. column 중 '국어' 열과 '영어' 열을 삭제하는 코드이다.
- columns이라는 파라미터를 사용하지 않는다면 위에 설명했듯이 axis=1 파라미터를 입력하면 된다.
<코드>
df5 = df.drop(['수학'], axis=1)
print(df5)
이름 국어 영어
0 YB 100 90
1 SW 70 60
2 EJ 40 30
3 HJ 10 5
| 1) Dataframe의 행, 열 이름 변경 2) Dataframe 조회 -. 인덱싱 -. 슬라이싱 -. 열 조회 -. 원소 조회 3) 행 열 추가하기 4) 행 삭제하기(drop) 4) 원소값 바꾸기 5) 결측치(NaN) 관련 |
오늘은 데이터프레임의 원소값을 바꾸는 방법과 결측치(NaN)을 처리하는 방법에 대해 정리하였다.
데이터프레임과 원본은 이전편과 그대로 사용 한다.
<이전 데이터프레임 코드>
import pandas as pd
#dataframe 생성(엑셀 파일 통해 생성)
df = pd.read_excel("df_test.xlsx", engine="openpyxl")
print(df)
이름 국어 영어 수학
0 YB 100 90 80
1 SW 70 60 50
2 EJ 40 30 20
3 HJ 10 5 1
1. 원소값 바꾸기
말 그대로 데이터 프레임의 특정 위치 원소값을 바꾸는 방법이다. 블로그 내용에 따르면 크게 2가지 방법이 있다. iloc( ) 와 loc( )함수를 사용하는 것이다. ioc( ) 와 loc( ) 는 이전 'Dataframe 데이터 조회하기'에서 다룬 적이 있다.
| 관련 포스팅 : 2021.04.03 - [코딩/Python] - [Python/파이썬] Pandas 기초 정리 : Dataframe 내부 데이터 조회 방법 |
간략히 요약하면 iloc( ) 는 데이터프레임의 숫자 인덱싱으로 위치에 접근하는 방식이고, loc( ) 는 실제 이름으로 접근하는 방식이다. 이전에는 조회를 했던 방식이라면 이번에는 같은 인덱싱 방법으로
1) iloc( ) 사용
<코드>
df.iloc[0,3] = "수정"
print(df)
이름 국어 영어 수학
0 YB 100 90 수정
1 SW 70 60 50
2 EJ 40 30 20
3 HJ 10 5 1
-. 파이썬의 인덱싱 번호는 0부터 시작함을 기억하자. [0,3]은 첫번째 해의 4번째 요소(YB의 수학)을 뜻한다.
2) loc( ) 사용
<코드>
df.loc[0,'수학'] = "0점"
df.loc[1,'영어'] = "0점"
print(df)
이름 국어 영어 수학
0 YB 100 90 0점
1 SW 70 0점 50
2 EJ 40 30 20
3 HJ 10 5 1-. loc는 인덱스와 컬럼명으로 접근하여 수정 가능
2. 결측치(NaN) 관련
결측치란 데이터프레임에서 값이 없는 것을 의미한다. 값이 없다는 것은 ""와 같은빈칸이 표시되는 것이 아니라 NaN이라는 결측치로 표시된다. DB에서 'null'과 같은 개념인 것 같다. 실제 규모가 큰 데이터프레임에서 이 NaN을 제거하는 전처리가 굉장히 중요하다고 한다.
(NaN : Not a Number)
이 결측치를 제거하는 방법은 크게 pandas의 dropna( ), fillna( ) 함수를 사용하는 방법이 있다. dropna는 결측치 NaN를 제거하는 방법이고, fillna( )는 다른 데이터로 채우는 방법이다.
결측치를 임의로 생성하기 위해 엑셀파일을 조금 수정해보았다. 엑셀파일의 빈칸은 데이터프레임에서 NaN으로 인식된다.
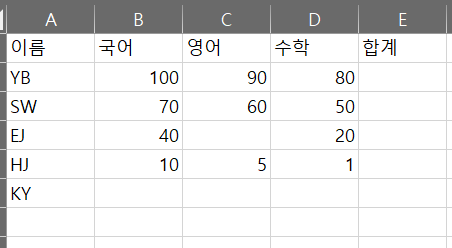
<위 엑셀파일 데이터프레임화 결과>
이름 국어 영어 수학 합계
0 YB 100.0 90.0 80.0 NaN
1 SW 70.0 60.0 50.0 NaN
2 EJ 40.0 NaN 20.0 NaN
3 HJ 10.0 5.0 1.0 NaN
4 KY NaN NaN NaN NaN
1) drona( )
dropna( )는 결측치를 제거한다. 여러 파라미터에 따라 어떻게 결측치가 제거되는지 정리해보았다.
A. 그냥 dropna( )를 사용할경우 결측치가 1개라도 있는 행(or열) 모두 제거
-. axis=0이면 행 기준으로 제거(default이므로 파라미터 생략해도 됨)
-. NaN이 모든 행에 있으므로 결과는 empty DataFrame인 것을 확인
<코드>
df.dropna(inplace=True)
print("제거 후")
print(df)
제거 후
Empty DataFrame
Columns: [이름, 국어, 영어, 수학, 합계]
Index: []
-. axis=1이면 열 기준으로 '이름'열만 살아남는다.
<코드>
df.dropna(axis=1, inplace=True)
print("제거 후")
print(df)
제거 후
이름
0 YB
1 SW
2 EJ
3 HJ
4 KY
B. 특정 열의 결측치만 제거하고싶은 경우 subset 파라미터를 사용한다.
-. 아래 코드는 '영어' 컬럼의 결측치가 있는 행을 제거한다.(2번,4번 인덱스 행 제거)
-. axis=0은 생략해도 무관(default값)
<코드>
df.dropna(subset=['영어'], axis = 0, inplace=True)
print(df)
이름 국어 영어 수학 합계
0 YB 100.0 90.0 80.0 NaN
1 SW 70.0 60.0 50.0 NaN
3 HJ 10.0 5.0 1.0 NaN
C. 1개의 열이 모두 결측치이거나 1개의 행이 모두 결측치인 경우를 how='all' 파라미터를 사용
-. axis=1(열 기준)으로 지정하여 실행하면 모든 값이 결측치였떤 '합계'열이 삭제 됨
-. axis=0으로 하면 모든 값이 결측치인 행이 없으므로 데이터프레임은 그대로임.
<코드>
df.dropna(how='all', axis=1, inplace=True)
print("제거 후")
print(df)
제거 후
이름 국어 영어 수학
0 YB 100.0 90.0 80.0
1 SW 70.0 60.0 50.0
2 EJ 40.0 NaN 20.0
3 HJ 10.0 5.0 1.0
4 KY NaN NaN NaN
D. 결측치가 아닌 데이터(non-NA) 개수를 기준으로 해서 행(or열)을 제거하려면 thresh 파라미터를 사용한다.
-. 결측치 아닌 data가 3개이상인 경우를 제외한 나머지 행 삭제(thresh=3)
-. 결과를 보면 알겠지만 결측치가 아닌 data가 3개 이하인 4번 행만 삭제된 것으로 확인
<코드>
import pandas as pd
#dataframe 생성(엑셀 파일 통해 생성)
df = pd.read_excel("df_test.xlsx", engine="openpyxl")
print("제거 전")
print(df)
df.dropna(thresh=3, inplace=True)
print("제거 후")
print(df)
제거 전
이름 국어 영어 수학 합계
0 YB 100.0 90.0 80.0 NaN
1 SW 70.0 60.0 50.0 NaN
2 EJ 40.0 NaN 20.0 NaN
3 HJ 10.0 5.0 1.0 NaN
4 KY NaN NaN NaN NaN
제거 후
이름 국어 영어 수학 합계
0 YB 100.0 90.0 80.0 NaN
1 SW 70.0 60.0 50.0 NaN
2 EJ 40.0 NaN 20.0 NaN
3 HJ 10.0 5.0 1.0 NaN
2) fillna( )
dropna( )는 결측치가 있는 행 또는 열을 제거하였다면 fillna( ) 는 결측치가 있는 행을 채우는 함수이다. fillna( ) 도 dropna( ) 와 같이 파라미터가 여러개 있지만 잘쓸 것같은 부분만 2가지정도 정리하고 나머지는 참고링크로 대체
A. 결측치(NaN)인 곳 모두 똑같은 값으로 채우기
-. dataframe.fillna('채울 값') 을 사용하면 아래와 같이 NaN이 모두 동일한 값으로 채워진다.
<코드>
import pandas as pd
#dataframe 생성(엑셀 파일 통해 생성)
df = pd.read_excel("df_test.xlsx", engine="openpyxl")
print("원본")
print(df)
df.fillna(0, inplace=True)
print("채운 후")
print(df)
원본
이름 국어 영어 수학 합계
0 YB 100.0 90.0 80.0 NaN
1 SW 70.0 60.0 50.0 NaN
2 EJ 40.0 NaN 20.0 NaN
3 HJ 10.0 5.0 1.0 NaN
4 KY NaN NaN NaN NaN
채운 후
이름 국어 영어 수학 합계
0 YB 100.0 90.0 80.0 0.0
1 SW 70.0 60.0 50.0 0.0
2 EJ 40.0 0.0 20.0 0.0
3 HJ 10.0 5.0 1.0 0.0
4 KY 0.0 0.0 0.0 0.0
B. 특정 열마다 다른 값으로 채우고 싶다면 value 파라미터를 사용한다.
-. 아래 코드와 같이 value에 대한 값은 딕셔너리 형태로 입력하면 된다.
<코드>
import pandas as pd
#dataframe 생성(엑셀 파일 통해 생성)
df = pd.read_excel("df_test.xlsx", engine="openpyxl")
print("원본")
print(df)
values = {'수학':"0점", '합계':"아직계산X"}
df.fillna(value=values, inplace=True)
print("채운 후")
print(df)
원본
이름 국어 영어 수학 합계
0 YB 100.0 90.0 80.0 NaN
1 SW 70.0 60.0 50.0 NaN
2 EJ 40.0 NaN 20.0 NaN
3 HJ 10.0 5.0 1.0 NaN
4 KY NaN NaN NaN NaN
채운 후
이름 국어 영어 수학 합계
0 YB 100.0 90.0 80 아직계산X
1 SW 70.0 60.0 50 아직계산X
2 EJ 40.0 NaN 20 아직계산X
3 HJ 10.0 5.0 1 아직계산X
4 KY NaN NaN 0점 아직계산X※ 참고링크
1. dropna( )
pandas.DataFrame.dropna — pandas 1.2.4 documentation
Determine if rows or columns which contain missing values are removed. Changed in version 1.0.0: Pass tuple or list to drop on multiple axes. Only a single axis is allowed.
pandas.pydata.org
2. fillna( )
pandas.DataFrame.fillna — pandas 1.2.4 documentation
If method is specified, this is the maximum number of consecutive NaN values to forward/backward fill. In other words, if there is a gap with more than this number of consecutive NaNs, it will only be partially filled. If method is not specified, this is t
pandas.pydata.org
Pandas의 dataframe끼리 결합하는 함수는 크게 Merge, Concat, Join이 있다. 이전에 다뤘던 append 함수도 있다. concat과 append는 dataframe 을 추가하는 방법에 대해 간단하게 언급했었다.
dataframe을 결합하는 함수로 Merge와 Concat을 많이 사용하는데 여러 파라미터값 설정을 통해 다양한 방식으로 결합할 수 있다.
오늘은 Concat에 대해 자주 쓰이는 파라미터를 기준으로 정리해보고자 한다.
먼저, concat과 merge의 차이점은 아래와 같다.
-. concat : 단순히 2개의 dataframe 을 합치는 것에 중점
-. merge : 2개의 dataframe을 설정한 기준대로 합치는 것(어떤 Column을 기준으로 하는가 등)
사실 위처럼 말로만 들으면 이해가 안가니 실제 코드로 이해해보고자 하였다. 내용이 많은 관계로 이번 포스팅은 concat에 대해서만 정리. 먼저 사용할 dataframe은 총 3개이다.(df1, df2, df3)
-. 엑셀 파일을 주로 활용하므로 1개의 엑셀파일에 3개의 sheet(수강생정보, 중간고사점수, 기말고사점수) 존재
-. 해당 시트별로 data들을 pd.read_excel 함수를 통해 dataframe화 하였음.
-. 아래 결과에서 보면 알겠지만 df2의 index 0,4번째는 test를 위해 일부로 똑같은 data를 입력하였다.
<코드>
#dataframe 생성(엑셀 파일 통해 생성)
df1 = pd.read_excel("df_test.xlsx", engine="openpyxl", sheet_name="수강생정보")
df2 = pd.read_excel("df_test.xlsx", engine="openpyxl", sheet_name="중간고사점수")
df3 = pd.read_excel("df_test.xlsx", engine="openpyxl", sheet_name="기말고사점수")
#dataframe 출력해보기 (df1, df2, df3)
print("원본")
print("\n")
print(df1)
print("\n")
print(df2)
print("\n")
print(df3)
#df1 : 수강생정보
이름 나이 연락처
0 YB 30 +81-0000-0000
1 SW 29 +81-0000-0001
2 EJ 28 +81-0000-0002
3 HJ 27 +81-0000-0003
4 James 20 +81-0000-0004
5 Borwn 21 +81-0000-0005
#df2 : 중간고사점수(index 0, 4번째 점수는 일부로 중복으로 입력)
이름 시험구분 국어 영어 수학
0 YB 중간고사 100 90 80
1 SW 중간고사 70 60 50
2 EJ 중간고사 40 5 20
3 HJ 중간고사 10 5 1
4 YB 중간고사 100 90 80
#df3 : 기말고사 점수
이름 시험구분 국어 영어 수학
0 YB 기말고사 100 100 100
1 SW 기말고사 70 70 70
2 EJ 기말고사 20 20 20
3 HJ 기말고사 10 10 10
1. 그냥 이어 붙이기(df2, df3)
-. 그냥 이어 붙인다.(합치기)
-. 뒤에서 다루겠지만 concat 파라미터 중 join = 'outer'가 default값이므로 합집합이 기본 결과이다.
-. 중복행이 그대로 입력된다.
-. 인덱스번호도 그대로 입력된다.
<코드>
print("#그냥 이어붙이기")
df_concat1 = pd.concat([df2,df3])
print(df_concat1)
#그냥 이어붙이기
이름 시험구분 국어 영어 수학
0 YB 중간고사 100 90 80
1 SW 중간고사 70 60 50
2 EJ 중간고사 40 5 20
3 HJ 중간고사 10 5 1
4 YB 중간고사 100 90 80
0 YB 기말고사 100 100 100
1 SW 기말고사 70 70 70
2 EJ 기말고사 20 20 20
3 HJ 기말고사 10 10 10
2. index 초기화하기, 또는 컬럼 중 인덱스로 설정하기(df2, df3)
-. index 번호를 초기화하려면 ignore_index = True를 넣어준다.(False가 default이므로 1번과 같은 결과가 나온다.)
-. 마찬가지로 index 중 0번, 4번과 같은 중복 데이터는 삭제되지 않는다.
<코드>
print("#index 초기화시키기")
df_concat2 = pd.concat([df2,df3], ignore_index=True)
print(df_concat2)
#index 초기화시키기
이름 시험구분 국어 영어 수학
0 YB 중간고사 100 90 80
1 SW 중간고사 70 60 50
2 EJ 중간고사 40 5 20
3 HJ 중간고사 10 5 1
4 YB 중간고사 100 90 80
5 YB 기말고사 100 100 100
6 SW 기말고사 70 70 70
7 EJ 기말고사 20 20 20
8 HJ 기말고사 10 10 10
-. 만약 dataframe의 일부 컬럼을 인덱스로 설정하려면 set_index 함수를 활용하자.
-. 이전 포스팅에서도 다뤘지만 함수 내부에 inplace=True를 입력하면 원본 dataframe이 수정된다.
(inplace=True를 활용하지 않으려면 새로운 변수에 수정한 df를 할당해야 한다.)
-. 마찬가지로 중복행은 삭제되지 않는다.
<코드>
print("#이름열을 index로 설정하기")
df_concat2.set_index('이름', inplace=True)
print(df_concat2)
#이름열을 index로 설정하기
시험구분 국어 영어 수학
이름
YB 중간고사 100 90 80
SW 중간고사 70 60 50
EJ 중간고사 40 5 20
HJ 중간고사 10 5 1
YB 중간고사 100 90 80
YB 기말고사 100 100 100
SW 기말고사 70 70 70
EJ 기말고사 20 20 20
HJ 기말고사 10 10 10
3. 열 단위로 이어 붙이기
-. 열 단위로 이어 붙이려면 axis=1 파라미터값을 입력하면 된다.
-. 1번,2번에서 다뤘던 방식은 행 단위로 이어 붙이는 방식이다.(axis=0)
-. 이전 포스팅에서 axis=0 vs axis=1 파라미터를 다룬적이 있으니 아래 링크를 참고
(참고링크 : 2021.04.11 - [코딩/Python] - [Python/파이썬] Pandas 기초 정리 : Dataframe 행, 열 삭제하기(drop 함수))
<코드>
print("#열단위로 이어 붙이기")
df_concat3 = pd.concat([df2,df3], axis=1)
print(df_concat3)
#열단위로 이어 붙이기
이름 시험구분 국어 영어 수학 이름 시험구분 국어 영어 수학
0 YB 중간고사 100 90 80 YB 기말고사 100.0 100.0 100.0
1 SW 중간고사 70 60 50 SW 기말고사 70.0 70.0 70.0
2 EJ 중간고사 40 5 20 EJ 기말고사 20.0 20.0 20.0
3 HJ 중간고사 10 5 1 HJ 기말고사 10.0 10.0 10.0
4 YB 중간고사 100 90 80 NaN NaN NaN NaN NaN
-. 위 결과에서 보듯이 열단위로 기말고사 탭부분이 추가되었다. 중복되는 열이름은 그대로 출력된다.
-. index 중 4번 YB의 경우 기말고사 내용이 없으므로 NaN(결측) 표시 된다.
4. 교집합, 합집합 출력하기(df1, df2)
-. 위에서 다뤘던 부분은 합집합이 출력되는 부분이다.(join='outer'가 default )
-. 2개의 df 중 Size가 일치하는 교집합 부분만 출력하려면 join='inner'를 입력한다.
<코드>
#join=outer는 합집합으로 default값, inner는 교집합으로 붙이기
print("#교집합")
df_concat4 = pd.concat([df1,df2], axis=1, join='inner')
print(df_concat4)
#교집합
이름 나이 연락처 이름 시험구분 국어 영어 수학
0 YB 30 +81-0000-0000 YB 중간고사 100 90 80
1 SW 29 +81-0000-0001 SW 중간고사 70 60 50
2 EJ 28 +81-0000-0002 EJ 중간고사 40 5 20
3 HJ 27 +81-0000-0003 HJ 중간고사 10 5 1
4 James 20 +81-0000-0004 YB 중간고사 100 90 80
-. 결과에서 보면 알겠지만 수강생 정보 중 이름 'brown' 의 정보는 생략된다.
-. 참고링크에서 교집합 출력하기라고 해서 봤는데 정확히는 교집합 출력이 아니라 Size가 맞는 dataframe까지만 합쳐서 보여주는것 을 말하는 것 같다.
-. 중간고사 df2에서 data 순서를 무작위로 바꿔보면 아래와 같이 나온다.
(이름 교집합 출력이 아닌 것을 알 수 있다.)
#교집합
이름 나이 연락처 이름 시험구분 국어 영어 수학
0 YB 30 +81-0000-0000 EJ 중간고사 40 5 20
1 SW 29 +81-0000-0001 HJ 중간고사 10 5 1
2 EJ 28 +81-0000-0002 YB 중간고사 100 90 80
3 HJ 27 +81-0000-0003 SW 중간고사 70 60 50
4 James 20 +81-0000-0004 YB 중간고사 100 90 80
-. 반대로 join='outer'를 설정하면 아래와 같이 결과가 나온다.(default이므로 파라미터값읍 입력하지 않아도 됨)
-. 위와 마찬가지로 dataframe 중 크기가 큰 df 기준으로 모든 data가 순차적으로 합쳐져 출력되는 것이다.
(index 4번행으 James와 YB를 보면 알 수 있음.)
-. borwn은 중간고사 성적이 없으므로 Nan 표시
<코드>
print("#합집합")
df_concat4 = pd.concat([df1,df2], axis=1, join="outer")
print(df_concat4)
#합집합
이름 나이 연락처 이름 시험구분 국어 영어 수학
0 YB 30 +81-0000-0000 YB 중간고사 100.0 90.0 80.0
1 SW 29 +81-0000-0001 SW 중간고사 70.0 60.0 50.0
2 EJ 28 +81-0000-0002 EJ 중간고사 40.0 5.0 20.0
3 HJ 27 +81-0000-0003 HJ 중간고사 10.0 5.0 1.0
4 James 20 +81-0000-0004 YB 중간고사 100.0 90.0 80.0
5 Borwn 21 +81-0000-0005 NaN NaN NaN NaN NaN
5. Series 이어 붙이기
-. concat은 Series를 기존 df에 이어붙일 수 있다.
-. 아래와 같이 새로운 Series type의 data를 3개 생성하였다.(sr1, sr2, sr3)
-. name이 붙은 Series는 Column 계열이며, index가 붙은 Series는 Row 계열이다.
<코드>
sr1 = pd.Series(['1등급','2등급','3등급','4등급'], name = '등급')
sr2 = pd.Series(['YB', 'SW', 'HJ', 'EJ'], name='이름')
sr3 = pd.Series(['james', 'brown', 'apple'], index = ['a','b','c'])
1) df와 Series 이어붙이기(열)
<코드>
#df와 Series 이어 붙이기(Column)
df_concat5= pd.concat([df2,sr1], axis=1)
print("df와 Series 이어 붙이기(Column)")
print(df_concat5)
이름시험구분 국어 영어 수학 등급
0 YB 중간고사 100 90 80 1등급
1 SW 중간고사 70 60 50 2등급
2 EJ 중간고사 40 5 20 3등급
3 HJ 중간고사 10 5 1 4등급
4 YB 중간고사 100 90 80 NaN
2) Series와 Series 이어붙이기(열)
<코드>
#Series와 Series 이어붙이기(Column)
df_concat6 = pd.concat([sr2,sr1], axis=1)
print("Series와 Series 이어붙이기(Column)")
print(df_concat6)
이름 등급
0 YB 1등급
1 SW 2등급
2 HJ 3등급
3 EJ 4등급
3) Series와 Series 이어붙이기(행)
<코드>
#Series와 Series 이어붙이기(Row)
df_concat7 = pd.concat([sr2,sr3], axis=0)
print("Series와 Series 이어붙이기(Row)")
print(df_concat7)
0 YB
1 SW
2 HJ
3 EJ
a james
b brown
c apple
참고링크
1. pandas.pydata.org/pandas-docs/stable/user_guide/merging.html
Merge, join, concatenate and compare — pandas 1.2.4 documentation
The concat() function (in the main pandas namespace) does all of the heavy lifting of performing concatenation operations along an axis while performing optional set logic (union or intersection) of the indexes (if any) on the other axes. Note that I say
pandas.pydata.org
2. yganalyst.github.io/data_handling/Pd_12/
merge 함수에 대해 정리한다. 이전 편에서 언급하였지만 concat은 겨우 단순히 2개의 데이터 프레임이나 시리즈를 합치는데 중점을 둔다. merge 함수의 경우 어떤 기준(key)을 가지고 데이터프레임을 결합할 수 있다.
아래 자주 쓰이는 몇가지 예시를 작성하였다. 이전 편과 마찬가지로 동일한 df1, df2, df3를 가지고 테스트하였다.
<df 생성 코드>
dataframe 생성(엑셀 파일 통해 생성)
df1 = pd.read_excel("df_test.xlsx", engine="openpyxl", sheet_name="수강생정보")
df2 = pd.read_excel("df_test.xlsx", engine="openpyxl", sheet_name="중간고사점수")
df3 = pd.read_excel("df_test.xlsx", engine="openpyxl", sheet_name="기말고사점수")
#df1 : 수강생정보
이름 나이 연락처
0 YB 30 +81-0000-0000
1 SW 29 +81-0000-0001
2 EJ 28 +81-0000-0002
3 HJ 27 +81-0000-0003
4 James 20 +81-0000-0004
5 Borwn 21 +81-0000-0005
#df2 : 중간고사점수(index 0, 4번째 점수는 일부로 중복으로 입력)
이름 시험구분 국어 영어 수학
0 YB 중간고사 100 90 80
1 SW 중간고사 70 60 50
2 EJ 중간고사 40 5 20
3 HJ 중간고사 10 5 1
4 YB 중간고사 100 90 80
#df3 : 기말고사 점수
이름 시험구분 국어 영어 수학
0 YB 기말고사 100 100 100
1 SW 기말고사 70 70 70
2 EJ 기말고사 20 20 20
3 HJ 기말고사 10 10 10
1. Merge 기본
-. df1과 df2 를 merge하면 서로 교집합이 되는 부분만 출력된다.
-. 2번에서 설명하겠지만 사실 파라미터 중 how='inner'가 default값이다.)
<코드>
print("기본 출력")
df_merge1 = pd.merge(df1, df2)
print(df_merge1)
기본 출력
이름 시험구분 국어 영어 수학 나이 연락처
0 YB 중간고사 100 90 80 30 +81-0000-0000
1 YB 중간고사 100 90 80 30 +81-0000-0000
2 SW 중간고사 70 60 50 29 +81-0000-0001
3 EJ 중간고사 40 5 20 28 +81-0000-0002
4 HJ 중간고사 10 5 1 27 +81-0000-0003
2. how 파라미터 사용하기
1) how = 'inner'
-. 위 1번과 마찬가지 결과이다.
-. how='inner'는 2개 데이터프레임간 교집합을 출력한다.
-. default이기 때문에 생략하여도 무관하다.
<코드>
print("교집합")
df_merge3 = pd.merge(df1, df3, how='inner')
print(df_merge3)
교집합
이름 나이 연락처 시험구분 국어 영어 수학
0 YB 30 +81-0000-0000 기말고사 100 100 100
1 SW 29 +81-0000-0001 기말고사 70 70 70
2 EJ 28 +81-0000-0002 기말고사 20 20 20
3 HJ 27 +81-0000-0003 기말고사 10 10 10
2) how ='outer'
-. outer로 설정시 합집합 결과를 출력한다. 합집합시 컬럼의 없는 데이터는 NaN처리 된다.
<코드>
print("합집합")
df_merge2 = pd.merge(df1, df3, how='outer')
print(df_merge2)
합집합
이름 나이 연락처 시험구분 국어 영어 수학
0 YB 30 +81-0000-0000 기말고사 100.0 100.0 100.0
1 SW 29 +81-0000-0001 기말고사 70.0 70.0 70.0
2 EJ 28 +81-0000-0002 기말고사 20.0 20.0 20.0
3 HJ 27 +81-0000-0003 기말고사 10.0 10.0 10.0
4 James 20 +81-0000-0004 NaN NaN NaN NaN
5 Borwn 21 +81-0000-0005 NaN NaN NaN NaN
3) how = 'left', how='right'
-. outer, inner 이외에 left와 right가 있다.
-. how=left or right 설정시 left는 merge함수의 왼쪽 데이터프레임 기준, right는 오른쪽 데이터 프레임 기준으로 결합
ex) pd.merge(left, right, how='left')
<코드>
print("df1(left)을 기준으로")
df_merge_left = pd.merge(df1,df3, how = 'left')
print(df_merge_left)
print("df3(right)을 기준으로")
df_merge_left = pd.merge(df1,df3, how = 'right')
print(df_merge_left)
df1(left)을 기준으로
이름 나이 연락처 시험구분 국어 영어 수학
0 YB 30 +81-0000-0000 기말고사 100.0 100.0 100.0
1 SW 29 +81-0000-0001 기말고사 70.0 70.0 70.0
2 EJ 28 +81-0000-0002 기말고사 20.0 20.0 20.0
3 HJ 27 +81-0000-0003 기말고사 10.0 10.0 10.0
4 James 20 +81-0000-0004 NaN NaN NaN NaN
5 Borwn 21 +81-0000-0005 NaN NaN NaN NaN
df3(right)을 기준으로
이름 나이 연락처 시험구분 국어 영어 수학
0 YB 30 +81-0000-0000 기말고사 100 100 100
1 SW 29 +81-0000-0001 기말고사 70 70 70
2 EJ 28 +81-0000-0002 기말고사 20 20 20
3 HJ 27 +81-0000-0003 기말고사 10 10 10
3. on 파라미터 사용하기
-. on 파라미터는 컬럼 또는 특정 인덱스를 기준으로 결합할 수 있다.
-. on으로 특정 컬럼을 설정하였을 경우 그 컬럼에 대한 데이터를 기준으로 모두 출력된다.
(복수 컬럼도 가능하다. on = ["이름", "나이"]와 같이 입력)
-. 아래의 결과를 확인해보자.('이름' 컬럼을 기준으로 출력)
<코드>
#df1의 이름열을 기준으로
print("\n")
print("df1(left)의 이름열을 기준으로")
df_merge4 = pd.merge(df1,df3, how = 'left', on="이름")
print(df_merge4)
#df3의 이름열을 기준으로
print("\n")
print("df3(right)의 이름열을 기준으로")
df_merge5 = pd.merge(df1,df3, how = 'right', on="이름")
print(df_merge5)
df1(left)의 이름열을 기준으로
이름 나이 연락처 시험구분 국어 영어 수학
0 YB 30 +81-0000-0000 기말고사 100.0 100.0 100.0
1 SW 29 +81-0000-0001 기말고사 70.0 70.0 70.0
2 EJ 28 +81-0000-0002 기말고사 20.0 20.0 20.0
3 HJ 27 +81-0000-0003 기말고사 10.0 10.0 10.0
4 James 20 +81-0000-0004 NaN NaN NaN NaN
5 Borwn 21 +81-0000-0005 NaN NaN NaN NaN
df3(right)의 이름열을 기준으로
이름 나이 연락처 시험구분 국어 영어 수학
0 YB 30 +81-0000-0000 기말고사 100 100 100
1 SW 29 +81-0000-0001 기말고사 70 70 70
2 EJ 28 +81-0000-0002 기말고사 20 20 20
3 HJ 27 +81-0000-0003 기말고사 10 10 10
4. 동일한 컬럼이 있는 다른 df 합쳐보기(df2, df3)
-. 동일한 컬럼명이 있는 데이터프레임(중간고사,기말고사)를 합쳐보았다.
-. 결과를 보면 동일한 컬럼명이 있을 경우 자동으로 왼쪽 df는 '_x', 오른쪽 df는 '_y' 접미사가 붙여져서 출력된다.
<코드>
print("동일한 컬럼명이 있는 df 합쳐보기, 이름열을 기준")
df_merge_left = pd.merge(df2, df3, on="이름")
print(df_merge_left)
동일한 컬럼명이 있는 df 합쳐보기, 이름열을 기준
이름 시험구분_x 국어_x 영어_x 수학_x 시험구분_y 국어_y 영어_y 수학_y
0 YB 중간고사 100 90 80 기말고사 100 100 100
1 YB 중간고사 100 90 80 기말고사 100 100 100
2 SW 중간고사 70 60 50 기말고사 70 70 70
3 EJ 중간고사 40 5 20 기말고사 20 20 20
4 HJ 중간고사 10 5 1 기말고사 10 10 10
-. x와 y대신 접미사를 별도로 설정하고 싶다면 suffixes라는 파라미터를 활용한다.
<코드>
print("suffixes 달기")
df_merge6 = pd.merge(df2, df3, on="이름", suffixes=("_중간", "_기말"))
print(df_merge6)
suffixes 달기
이름 시험구분_중간 국어_중간 영어_중간 수학_중간 시험구분_기말 국어_기말 영어_기말 수학_기말
0 YB 중간고사 100 90 80 기말고사 100 100 100
1 YB 중간고사 100 90 80 기말고사 100 100 100
2 SW 중간고사 70 60 50 기말고사 70 70 70
3 EJ 중간고사 40 5 20 기말고사 20 20 20
4 HJ 중간고사 10 5 1 기말고사 10 10 10
5. indicator='컬럼명' : merge 사용시 합쳐지는 df에 대한 정보(출처?)
-. merge 사용시 합쳐진 데이터프레임 결과에서 각 데이터의 출처(left, right)를 알고 싶으면 indicator 파라미터 사용
-. 결합하는 2개 모두 데이터프레임에 있을 경우 : both
-. 왼쪽 데이터프레임(df1)에만 있을 경우 : left_only
-. 오른쪽 데이터프레임(df2)에만 있을 경우 : right_only
<코드>
print("indicator 정보")
df_merge7 = pd.merge(df1, df3, how='outer', indicator='indicator 정보')
print(df_merge7)
indicator 정보
이름 나이 연락처 시험구분 국어 영어 수학 indicator 정보
0 YB 30 +81-0000-0000 기말고사 100.0 100.0 100.0 both
1 SW 29 +81-0000-0001 기말고사 70.0 70.0 70.0 both
2 EJ 28 +81-0000-0002 기말고사 20.0 20.0 20.0 both
3 HJ 27 +81-0000-0003 기말고사 10.0 10.0 10.0 both
4 James 20 +81-0000-0004 NaN NaN NaN NaN left_only
5 Borwn 21 +81-0000-0005 NaN NaN NaN NaN left_only
'제품추천 > IT' 카테고리의 다른 글
| 나만의 영어 발음 오디오 만들기 (65) | 2024.03.10 |
|---|---|
| Be-Blogger with Notion 비블로거 위드 노션 블로그 자동화 프로그램 (0) | 2024.03.09 |
| 파워포인트 자동 보고서 만들기 feat. 파이썬 (0) | 2023.11.07 |
| 파이썬 주식 분석 자동 프로그램 만들기 (1) | 2023.11.04 |
| [파이썬] 보고서 생성 및 전송 자동화 (0) | 2023.11.02 |