


부동산 매물 정보 수집하기 - 부동산 데이터 네이버 부동산 크롤링 및 가공 #2 ㅣ 현대 사회에서 데이터는 매우 중요한 자산입니다. 특히 부동산 시장에서는 아파트 단지에 대한 정보가 투자 결정에 큰 영향을 미치기 때문에, 이를 효율적으로 수집하는 방법이 필요합니다. 이번 포스트에서는 Python을 사용하여 아파트 단지 정보를 크롤링하는 방법에 대해 자세히 알아보겠습니다. 이 과정에서는 Naver의 부동산 API를 활용하여 세대수, 사용승인일, 평형별 면적 정보 등을 수집할 것입니다.
부동산 매물 정보 수집하기 - 부동산 데이터 네이버 부동산 크롤링 및 가공 #2

오늘 시리즈는 부동산 매물 정보 수집하기 - 부동산 데이터 네이버 부동산 크롤링 및 가공 편입니다. 아직 1편을 못 보신 분들이라면 1편을 먼저 읽고 오시는게 도움이 되실 수 있습니다.
2024.09.15 - [부동산/자동화 프로젝트] - 부동산 매물 정보 수집하기 - 부동산 데이터 네이버 부동산 크롤링 및 가공 #1
1. 크롤링의 필요성
부동산 시장은 끊임없이 변화하고 있으며, 이에 따라 아파트 단지에 대한 정보도 지속적으로 업데이트됩니다. 투자자, 구매자, 임대인 등 다양한 이해관계자들은 이러한 정보를 신속하게 파악해야 합니다. 하지만 수작업으로 정보를 수집하는 것은 시간과 노력이 많이 소요되므로, 자동화된 방법이 필요합니다. Python은 이러한 작업을 수행하기에 적합한 언어로, 다양한 라이브러리를 통해 웹 크롤링을 쉽게 구현할 수 있습니다.
2. 필요한 라이브러리 설치
Python을 사용하여 웹 크롤링을 수행하기 위해서는 몇 가지 라이브러리를 설치해야 합니다. 주로 사용되는 라이브러리는 requests, BeautifulSoup, 그리고 json입니다. 아래의 명령어를 사용하여 필요한 라이브러리를 설치할 수 있습니다.
pip install requests beautifulsoup4 pandas
3. API 요청을 위한 기본 설정
Naver의 부동산 API를 사용하여 아파트 단지 정보를 요청하기 위해서는 API의 URL과 요청 헤더를 설정해야 합니다. 아래는 기본적인 설정 코드입니다.
import requests
import json
from bs4 import BeautifulSoup
url = "https://new.land.naver.com/api/complexes/overview/"
param = {
'complexNo': '23620' # 조회할 아파트 단지 번호
}
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.220 Whale/1.3.51.7 Safari/537.36',
'Referer': 'https://m.land.naver.com/'
}
위 코드에서 complexNo는 조회하고자 하는 아파트 단지의 고유 번호입니다. 이 번호는 Naver 부동산 사이트에서 각 단지의 URL을 통해 확인할 수 있습니다.
4. 아파트 단지 정보 요청
이제 설정한 URL과 헤더를 사용하여 API에 GET 요청을 보내고, 응답을 받아 아파트 단지 정보를 추출해 보겠습니다.
먼저 단지를 추출할 수 있는 request 주소를 한번 살펴 보겠습니다.
아래 캡쳐 화면은 단지 정보를 보여주는 링크를 Postman으로 Request 문과 호출 결과를 조회한 화면입니다. 화면에서 붉은색 상자는 링크를 입력하는 곳이며, 파란색 상자는 Python Request문을 생성해 줍니다. 그리고 초록색 상자는 해당 Requst 호출의 결과를 보기쉽게 보여줍니다. 주의할 점은 생성된 Request 문의 header 값을 추가해주어야지 Naver 사이트에서 원하는 결과값을 얻을 수 있습니다. 아래 코드에 해당 header 값이 있습니다.
먼저 Postman을 접속해서 해당 주소를 검색해보겠습니다.
Postman API Platform | Sign Up for Free
Postman is an API platform for building and using APIs. Postman simplifies each step of the API lifecycle and streamlines collaboration so you can create better APIs—faster.
www.postman.com
https://new.land.naver.com/api/complexes/overview/23620?complexNo=23620
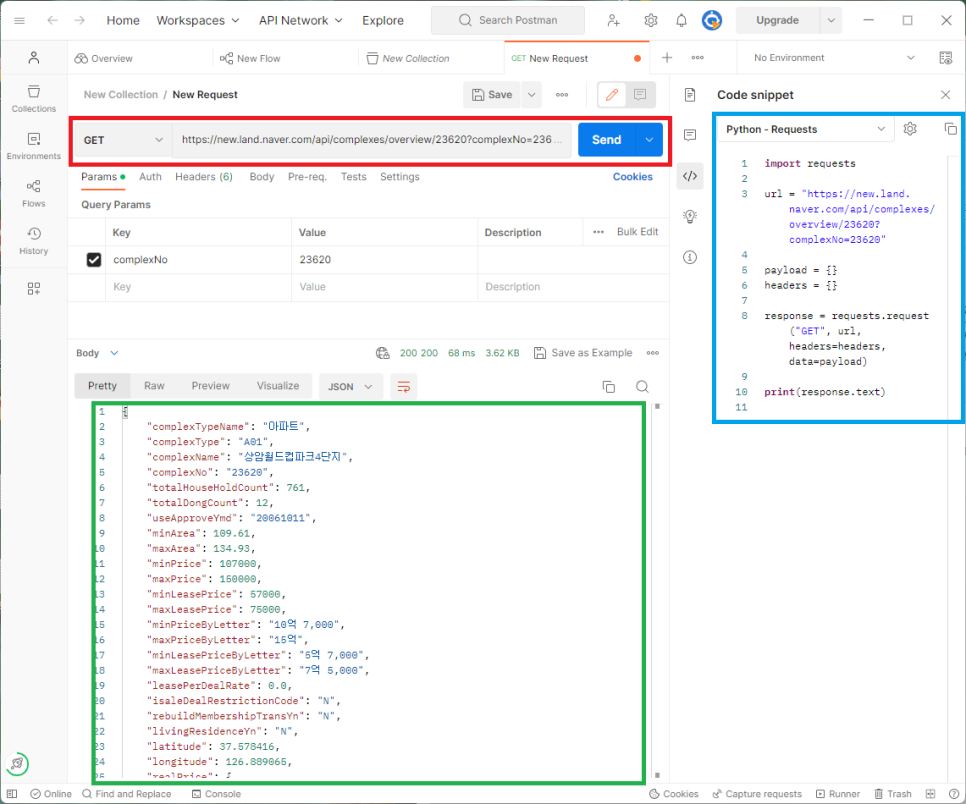
Postman을 통해 보여지는 단지 정보의 key와 value입니다.
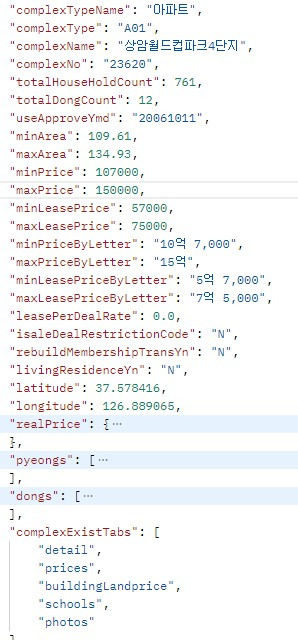
Request 정보를 토대로 아래와 같이 코드를 작성해봅니다.
import requests
import json
import pandas as pd
import requests
from bs4 import BeautifulSoup
url = "https://new.land.naver.com/api/complexes/overview/"
param = {
'complexNo': '23620'
}
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.220 Whale/1.3.51.7 Safari/537.36',
'Referer': 'https://m.land.naver.com/'
}
payload = {}
response = requests.request("GET", url+param['complexNo'], params=param, headers=header, data=payload)
u = response.url
temp = json.loads(response.text)
print("\n\n단지명: %s 사용승인일: %s 세대수: %s \n" \
%(temp['complexName'], temp['useApproveYmd'], temp['totalHouseHoldCount']))
# 추가 정보 조회
url2 = "https://m.land.naver.com/complex/info/"+ param['complexNo'] + "?ptpNo=1"
response2 = requests.request("GET", url2, headers=header, data=payload)
doc = BeautifulSoup(response2.text, 'html.parser')
titles = doc.find_all('span', class_='tit')
datas = doc.find_all('span', class_='data')
tmp = dict()
for title, data in zip(titles, datas):
tmp.setdefault(title.text, data.text.replace("\n", "").strip())
print("용적률: " + tmp['용적률'] + " 건폐율: " + tmp['건폐율'])
# 평형 별 정보 조회
temp2 = temp['pyeongs']
for item in temp2:
print("분양: %6s m^2 [ %-5s] 전용: %5s m^2(%5s 평)" \
%(item['supplyArea'], item['pyeongName2'], item['exclusiveArea'], item['exclusivePyeong']))필요한 라이브러리 불러오기
import requests
import json
import pandas as pd
from bs4 import BeautifulSoup- requests: HTTP 요청을 보내고 응답을 받기 위해 사용됩니다.
- json: API에서 받은 JSON 데이터를 처리하는 데 사용됩니다.
- pandas: 데이터 처리를 용이하게 하기 위한 라이브러리. 현재 코드에서는 사용되지 않았지만 나중에 데이터를 처리할 때 유용합니다.
- BeautifulSoup: HTML을 파싱하고 필요한 정보를 추출하기 위해 사용됩니다.
API URL과 요청 매개변수 설정
url = "https://new.land.naver.com/api/complexes/overview/"
param = {
'complexNo': '23620'
}- url: 네이버 부동산 API의 단지 정보에 접근하는 URL입니다.
- param: 조회하려는 특정 아파트 단지의 고유번호가 담긴 파라미터로, '23620'은 "상암월드컵파크 4단지"를 나타냅니다.
요청 헤더 설정
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.220 Whale/1.3.51.7 Safari/537.36',
'Referer': 'https://m.land.naver.com/'
}- User-Agent: 웹사이트에서 요청을 받을 때 어떤 브라우저로 접근하는지 인식하는 값입니다. 웹 서버에서 비정상적인 접근을 차단하는 경우가 있어, 이 값을 설정하여 사람처럼 보이도록 합니다.
- Referer: API 요청을 네이버 모바일 부동산 사이트에서 온 것처럼 보이게 만듭니다.
단지 정보 요청 및 출력
response = requests.request("GET", url + param['complexNo'], params=param, headers=header, data={})
temp = json.loads(response.text)
print("\n\n단지명: %s 사용승인일: %s 세대수: %s \n" \
%(temp['complexName'], temp['useApproveYmd'], temp['totalHouseHoldCount']))- requests.request("GET", ...): GET 요청을 통해 API로부터 데이터를 가져옵니다.
- json.loads(response.text): API 응답을 JSON 형식으로 변환합니다.
- print: 단지명, 사용승인일, 세대수를 출력합니다. 각각 temp에서 추출된 정보입니다.
추가 단지 정보 요청
url2 = "https://m.land.naver.com/complex/info/"+ param['complexNo'] + "?ptpNo=1"
response2 = requests.request("GET", url2, headers=header, data={})
doc = BeautifulSoup(response2.text, 'html.parser')- url2: 네이버 모바일 부동산 웹페이지에서 해당 단지에 대한 추가 정보를 가져오는 URL입니다.
- BeautifulSoup: HTML 응답을 파싱하여 필요한 정보를 쉽게 추출할 수 있도록 합니다.
용적률, 건폐율 추출
titles = doc.find_all('span', class_='tit')
datas = doc.find_all('span', class_='data')
tmp = dict()
for title, data in zip(titles, datas):
tmp.setdefault(title.text, data.text.replace("\n", "").strip())
print("용적률: " + tmp['용적률'] + " 건폐율: " + tmp['건폐율'])- doc.find_all('span', class_='tit'): HTML에서 'span' 태그 중 클래스가 'tit'인 모든 요소를 찾습니다. 이는 제목(용적률, 건폐율 등)에 해당합니다.
- zip: titles와 datas를 한 쌍으로 묶어 딕셔너리에 저장합니다.
- print: 용적률과 건폐율을 출력합니다.
7. 평형별 정보 조회
temp2 = temp['pyeongs']
for item in temp2:
print("분양: %6s m^2 [ %-5s] 전용: %5s m^2(%5s 평)" \
%(item['supplyArea'], item['pyeongName2'], item['exclusiveArea'], item['exclusivePyeong']))- temp2 = temp['pyeongs']: 단지 정보에서 평형별 데이터를 추출합니다.
- for item in temp2: 각 평형의 정보를 순회하며 분양 면적과 전용 면적을 출력합니다.
'부동산 > 자동화 프로젝트' 카테고리의 다른 글
| [고급] 부동산 정보 필터 고도화 - 네이버 매물 정리하기 2 (5) | 2024.10.01 |
|---|---|
| [고급] 부동산 정보 필터 고도화 - 네이버 매물 정리하기 (3) | 2024.09.30 |
| 부동산 매물 정보 수집하기 - 부동산 데이터 네이버 부동산 크롤링 및 가공 #1 (3) | 2024.09.27 |
| 파이썬 부동산 매매가 조회 프로그램 만들기 4편 (전국 데이터) (3) | 2024.09.26 |
| 파이썬 부동산 매매가 조회 프로그램 만들기 3편 (서울아파트 컬럼 정리) (1) | 2024.09.25 |